GPT Image 2 em profundidade: 12 exemplos reais para todos os casos de uso principais
O GPT Image 2 — lançado também como ChatGPT Images 2.0 — entrou em funcionamento em 21 de abril de 2026. É o primeiro modelo de geração de imagens independente da OpenAI: desacoplado do pipeline do GPT-4o, reconstruído com inferência de passagem única e o primeiro modelo de imagem na linha da OpenAI com raciocínio nativo integrado à arquitetura.
Os números principais: precisão de renderização de texto 99%+, resolução nativa 2K (até 4K em paisagem), proporções de aspecto de 3:1 ultra-largo a 1:3 ultra-vertical e — com o modo Thinking — até oito imagens coerentes a partir de um único prompt com personagens consistentes em todo o lote.
Testamos 12 casos de uso relevantes para produção. Cada exemplo abaixo foi gerado com GPT Image 2 usando o prompt exibido.
O que mudou em relação ao GPT Image 1.5
| Funcionalidade | GPT Image 1.5 | GPT Image 2 |
|---|---|---|
| Arquitetura | Pipeline de imagem GPT-4o (dois estágios) | Modelo independente, inferência de passagem única |
| Resolução máxima | 1536×1024 (paisagem) | 3840×2160 (4K paisagem) |
| Precisão de renderização de texto | ~70% (apenas latino) | 99%+, multilíngue |
| Integração de raciocínio | Nenhuma | Modo Thinking nativo (com pesquisa na web) |
| Lote de múltiplas imagens | Não suportado | Até 8 imagens por prompt (modo Thinking) |
| Edição em linguagem natural | Não suportado | Descreva a alteração — sem máscara necessária |
| Intervalo de proporção de aspecto | 1:1 e predefinições fixas | 3:1 a 1:3, qualquer resolução dentro das restrições |
| String do modelo da API | gpt-image-1.5 | gpt-image-2 |
O GPT Image 2 não é uma atualização de imagem do GPT-4o. É uma reconstrução do zero: metadados diferentes no PNG de saída, caminho de inferência diferente e um pipeline de renderização de texto completamente diferente. A OpenAI o posiciona como um 'parceiro de pensamento visual' construído para fluxos de trabalho de produção, não para exploração criativa.
1. Retrato fotorrealista
Os retratos continuam sendo o benchmark mais exigente para geração de imagens: textura da pele, dispersão abaixo da superfície, profundidade de campo e proporção facial precisam estar corretos ao mesmo tempo. O GPT Image 2 os trata com o que a própria documentação do modelo chama de renderização 'sensível à identidade' — detalhes finos se mantêm em todo o quadro, não apenas no recorte central.
Em nosso teste, solicitamos um retrato de close-up com características específicas de iluminação e lente. Sem pós-processamento, sem upscaling — saída direta do modelo em alta qualidade, 1024×1024.

Prompt
A photorealistic close-up portrait of a South Asian woman in her late 20s, soft diffused window light from the upper left, very shallow depth of field with background completely out of focus, warm neutral background, 85mm lens perspective. Ultra-fine skin texture — visible pores, subtle smile lines near the eyes, one small birthmark on the left cheek. Dark brown eyes, natural makeup. Hair loosely pinned, a few strands falling forward. Shot on a medium format digital camera. No filters. No color grading.
Resultado: A textura da pele é renderizada ao nível dos poros. A direção da iluminação é fisicamente consistente — preenchimento de sombra no lado direito, luz de borda traçando a orelha — sem especificação manual de iluminação além de 'luz de janela do canto superior esquerdo'. A mancha e as linhas de sorriso estão presentes.
2. Renderização de texto multilíngue
A renderização de texto é a capacidade definidora do GPT Image 2 e a maior lacuna entre ele e todos os modelos concorrentes. A OpenAI conseguiu isso introduzindo um caminho tipográfico que escreve glifos como formas vetoriais antes de rasterizá-los na cena.
O resultado prático: texto em inglês, japonês, coreano, árabe, chinês, turco e hebraico é renderizado corretamente na primeira tentativa na grande maioria dos casos.
Testamos um pôster de festival de música em japonês-inglês misturado — um dos cenários de renderização de texto mais difíceis.

Prompt
A bold music festival poster. Headline: "音楽の未来" in large brushstroke kanji, centered at the top third. Directly below it in a clean geometric sans-serif: "FUTURE SOUNDS FESTIVAL". Venue and date in smaller white type at the bottom: "Shibuya O-EAST · Tokyo · June 14 2026". Dark background, electric teal and magenta neon glow. All text must be fully legible and correctly formed. No decorative elements that obscure the type.
Resultado: Todos os traços de kanji estão corretamente formados. O título em inglês e a linha do local são completamente legíveis. Limitação conhecida: árabe e hebraico com diacríticos completos em tamanhos de ponto muito pequenos produzem ocasionalmente erros de glifo individual.
3. Fotografia de produto
A fotografia de produto para e-commerce é um dos casos de uso mais valiosos comercialmente para o GPT Image 2. O modelo lida com reflexos, sombras de superfície, texturas de materiais — vidro, metal fosco, papel kraft, cerâmica — e profundidade de campo correta.
Testamos um flat lay de skincare premium — uma categoria de prompt de benchmark porque requer destaques especulares corretos no vidro, texto de etiqueta legível e posicionamento convincente de pétalas.

Prompt
A high-end skincare flat lay on a smooth white marble surface. Center: a frosted glass serum bottle with a gold dropper cap. The label reads "LUMIÈRE SÉRUM — 30ml" in clean black serif type. Surrounding it: three dried white peonies, scattered rose petals, a small jade facial roller, and a cream-colored linen cloth slightly crumpled in the bottom-left corner. Soft north window light from above-left. Clean drop shadow under each object. No artificial studio look — feels like a magazine editorial. Shot from directly above. 16:9 crop.
Resultado: O texto da etiqueta 'LUMIÈRE SÉRUM — 30ml' é renderizado corretamente, incluindo o É acentuado. A textura do vidro fosco e os destaques da tampa conta-gotas dourada são precisos. O posicionamento das pétalas parece orgânico, não algoritmicamente regular.
4. Embalagem de produto com etiquetas legíveis
As maquetes de embalagem requerem a versão mais difícil da renderização de texto: listas de ingredientes, tabelas nutricionais, texto legal e tipografia de marca, tudo em uma superfície tridimensional com distorção curva e textura de material.
Antes do GPT Image 2, isso era impossível sem um composto de ferramenta de design. O GPT Image 2 é o primeiro modelo capaz de renderizar uma maquete de embalagem com texto correto ao longo de todo — não apenas o título.

Prompt
A photorealistic standing coffee bag mockup. The bag is matte black kraft paper with a natural linen texture stripe across the center. Brand name on the front: "ALTIPLANO" in a bold, wide uppercase serif, letterpressed in gold foil. Below it: "Single Origin · Ethiopian Yirgacheffe" in a smaller clean sans-serif. Bottom strip: "Notes: Blueberry · Jasmine · Brown Sugar". The bag has a tin-tie closure at the top and a circular degassing valve on the lower right. Dark studio background with a single dramatic spotlight from above. Realistic paper texture, no plastic sheen.
Resultado: Todos os elementos de texto são renderizados corretamente, incluindo o subtítulo e as notas de degustação. A textura do papel, o fecho tie-tin e a válvula de desgaseificação são fisicamente plausíveis. Diretamente utilizável em um pitch deck ou listagem de e-commerce sem retoques.
5. Material criativo de marketing com texto na imagem
As equipes de marketing sobrepunham texto em imagens geradas por IA no Figma ou Photoshop porque o texto do modelo era pouco confiável. O GPT Image 2 elimina essa etapa: títulos, CTAs e corpo do texto podem ser especificados no prompt e serão renderizados corretamente dentro da imagem, prontos para implantação sem uma passagem de design separada.
Testamos um formato de anúncio para redes sociais — a variante mais difícil desse fluxo de trabalho, pois requer texto CTA correto, imagem do produto e hierarquia de layout, tudo em uma única geração.

Prompt
A clean social media ad for a premium running shoe brand. Split layout: left half shows a dramatic close-up of a white and electric blue running shoe on a wet asphalt surface reflecting city lights. Right half is a solid dark navy panel. On the navy panel, stacked vertically: bold white headline "RUN FASTER." then a small white separator line, then secondary copy in light grey "Engineered for your fastest 5K." then below that a solid lime green CTA button with the text "SHOP NOW" in black. All text must be perfectly legible. Modern, premium athletic aesthetic.
6. Infográfico e diagrama passo a passo
Os infográficos exigem que o modelo gerencie simultaneamente layout, hierarquia tipográfica, iconografia, setas direcionais e precisão das informações — uma combinação que faz a maioria dos modelos de imagem falhar. O GPT Image 2 lida bem com essa categoria para diagramas estilizados e instrutivos.
Testamos um diagrama educacional passo a passo com etiquetas numeradas e conectores de seta.
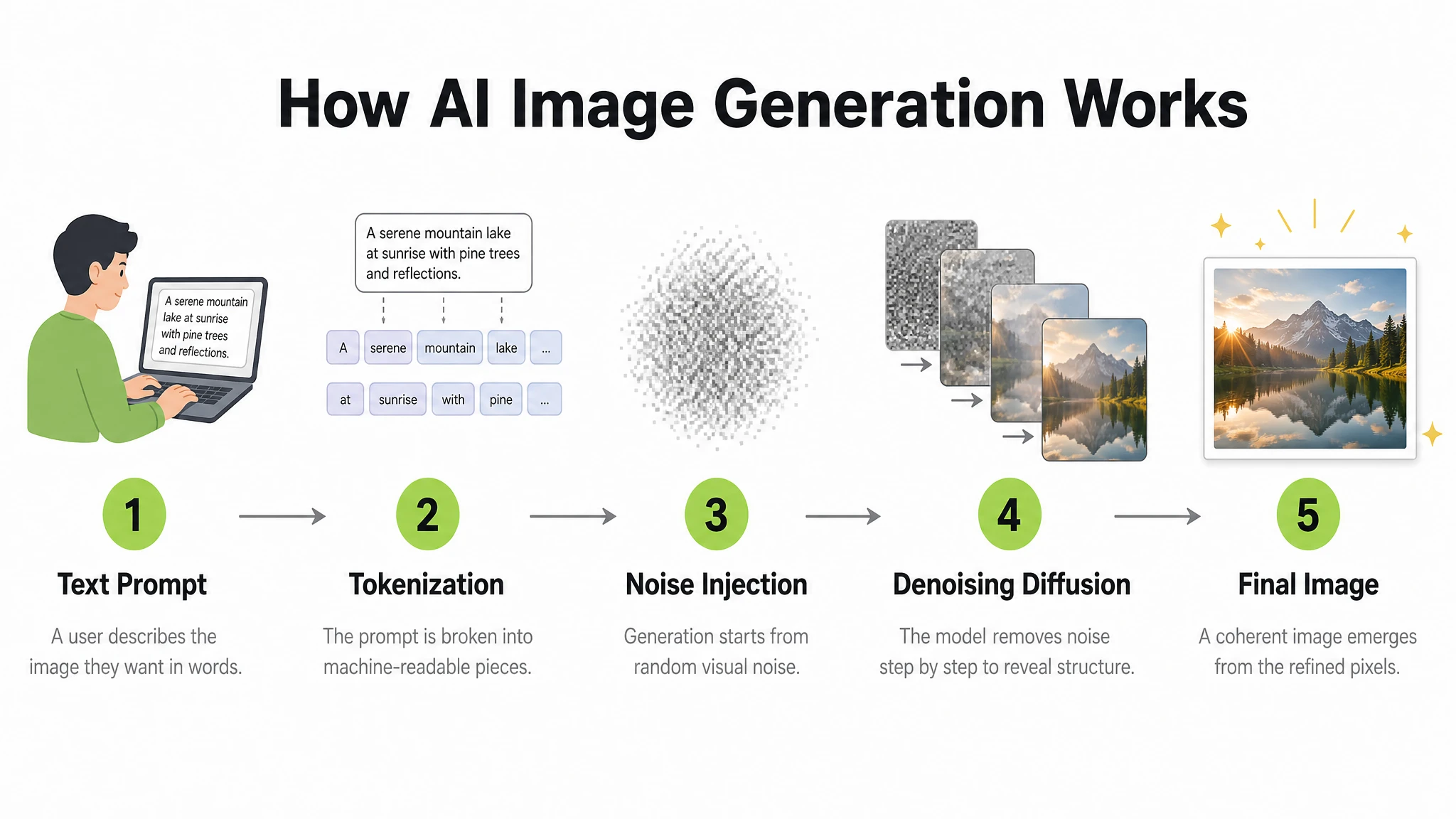
Prompt
A clean, modern educational infographic titled "How AI Image Generation Works" showing 5 steps in a left-to-right horizontal flow. Step 1: "Text Prompt" — icon of a person typing. Step 2: "Tokenization" — text being split into tokens. Step 3: "Noise Injection" — abstract Gaussian noise cloud. Step 4: "Denoising Diffusion" — blurry image sharpening. Step 5: "Final Image" — glowing completed photograph. Each step has: a bold number in a lime green circle, a simple flat icon above, the step title in bold dark text, and a one-line description in lighter grey below. Steps connected by clean horizontal arrows. White background. Clear typographic hierarchy. No decorative clutter.
7. Maquete de UI e design de interface de aplicativo
A geração de maquetes de UI é um novo caso de uso que o GPT Image 2 trata melhor do que qualquer modelo anterior. A combinação de renderização de texto precisa, raciocínio de layout e detalhes ao nível do ícone torna possível gerar uma tela de aplicativo ou painel credível sem uma ferramenta de design.
Testamos um painel de aplicativo bancário móvel: um prompt pesado em layout com etiquetas de navegação, saldos de conta, linhas de histórico de transações e um elemento de cartão.
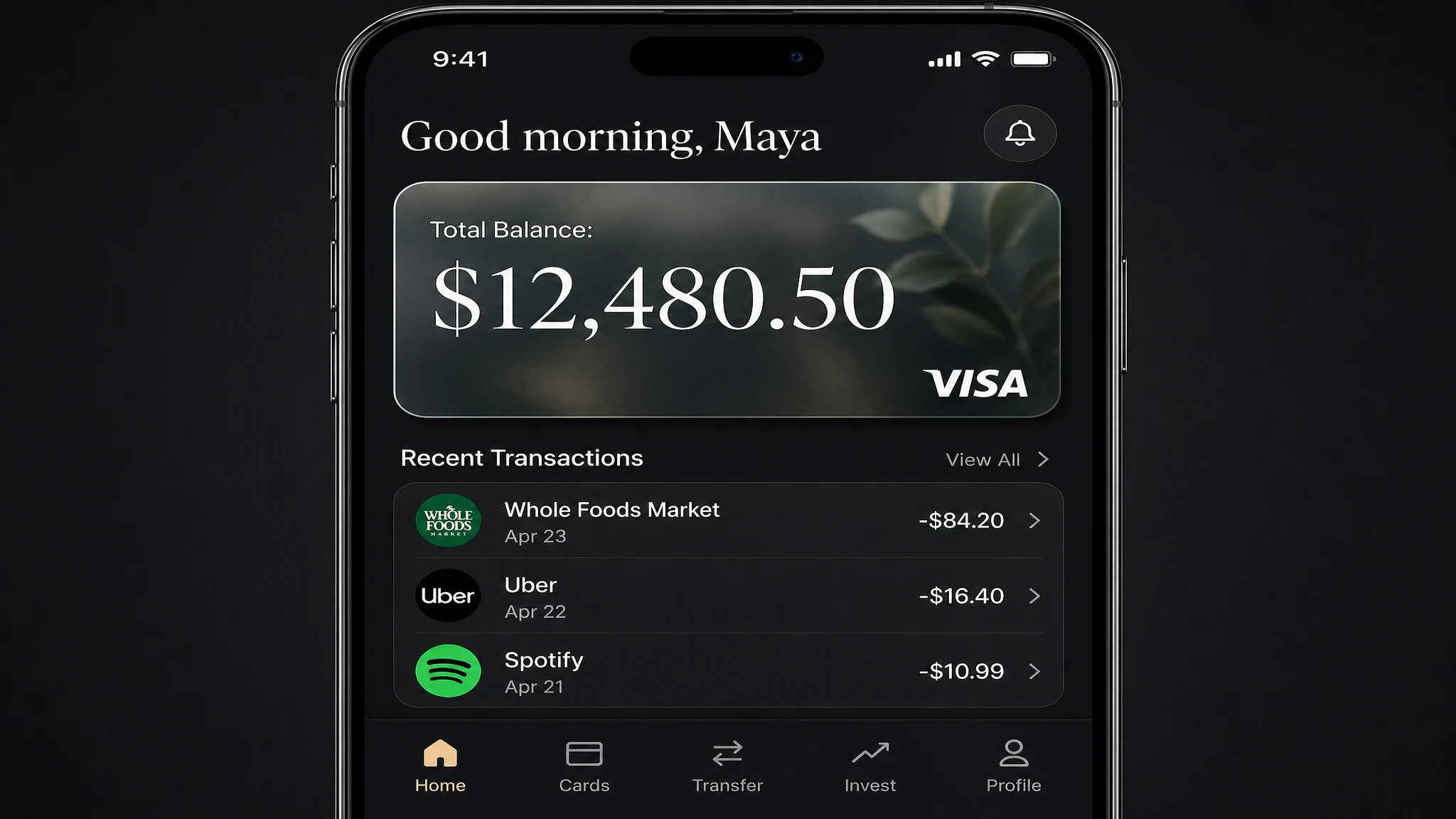
Prompt
A photorealistic mobile app UI mockup for a premium digital bank. Dark charcoal background. Top section: user greeting "Good morning, Maya" in white. Below: a frosted glass card element showing "Total Balance: $12,480.50" in a large white serif, with a small visa logo in the bottom right. Below the card: a section titled "Recent Transactions" with three rows — each row has a category icon on the left, merchant name and date in the center, and amount on the right (e.g. "Whole Foods Market · Apr 23 · -$84.20"). Bottom navigation bar with five icons: Home, Cards, Transfer, Invest, Profile. All labels must be legible. Clean, minimal, premium fintech aesthetic.
Resultado: O valor do saldo, as linhas de transação e as etiquetas de navegação são todas renderizadas corretamente. O elemento de cartão de vidro fosco tem translucidez precisa. Útil como mood board ou protótipo para partes interessadas — não código pronto para produção, mas suficiente para comunicar a direção do design sem um arquivo Figma.
8. Modo Thinking: Consistência de múltiplas imagens
O modo Thinking é a capacidade mais diferenciada do GPT Image 2 e sua maior distância em relação a qualquer outro modelo atual de geração de imagens. Quando ativado, o modelo raciocina sobre o prompt antes de gerar — gastando mais ou menos computação dependendo da complexidade — e pode pesquisar na web durante essa fase de raciocínio.
Isso é diretamente útil para ilustração de livros infantis, storyboards, campanhas de marca sequenciais e arte conceitual de jogos. O acesso ao modo Thinking requer uma assinatura ChatGPT Plus, Pro, Business ou Enterprise.

Prompt
Generate 4 scenes featuring the same character: Chef Milo, a cheerful stocky man in his 40s with a thick red-orange beard, round wire-rimmed glasses, and a white double-breasted chef coat with a small anchovy embroidered on the chest pocket. Scene 1: Milo in a busy open kitchen, plating a dish with tweezers, intense concentration. Scene 2: Milo at a morning market, selecting vegetables, smiling at a vendor. Scene 3: Milo eating a street taco by a food cart, genuine delight on his face. Scene 4: Milo teaching a cooking class, holding a carbon steel wok, students visible in the background. Keep Milo's face, beard, glasses, and coat identical across all four scenes. Cinematic photography style.
Isso é genuinamente novo: nenhuma outra API de geração de imagens oferece saída de lote multi-imagem com continuidade de personagens em uma única chamada. Para conteúdo sequencial — storyboards, histórias ilustradas, campanhas de múltiplas cenas — isso muda fundamentalmente a equação de produção.
9. Edição de imagens em linguagem natural
O GPT Image 2 suporta edição de imagens através do endpoint /v1/images/edits. Você carrega uma imagem existente e descreve a alteração em linguagem simples. O modelo aplica edições direcionadas sem regenerar a imagem completa, preservando identidade, composição e iluminação enquanto modifica apenas o elemento especificado.
Trocas de fundo, adições de objetos, alterações de iluminação, ajustes de cor de roupas e transferências de estilo funcionam todos apenas por descrição de texto.

Prompt
[Edit instruction applied to an existing studio product shot of a glass perfume bottle on white background] Change the background from the plain white studio background to a warm, rustic wooden table surface with soft dappled sunlight coming from the left. Keep the bottle, its reflections, and its shadow exactly as they are. The new background should feel like a high-end lifestyle photograph taken in a sunlit Parisian apartment.
10. Controle de estilo artístico e cinematográfico
O GPT Image 2 cobre mais de 50 estilos artísticos reconhecidos, do fotorrealismo à pintura a óleo, aquarela, anime, pixel art, impressão de meio-tom e cyberpunk neon. O modelo segue fielmente os descritores de estilo nos prompts sem derivar para uma estética de IA genérica.
Testamos um fotograma cinematográfico de alto contraste: um gênero específico, configuração de iluminação e gradação de cor todos especificados juntos.

Prompt
A cinematic still in the style of contemporary neo-noir. A lone figure in a dark trench coat walks down a rain-slicked urban alley at 2am. Reflections of neon signs — one red kanji, one amber "HOTEL" in script — pool on the wet pavement. Shallow depth of field keeps the background signage slightly soft. Color grade: deep teal shadows, warm amber highlights — classic film noir color separation. Low-key side lighting from a practical wall sconce off screen right. The figure's face is partially in shadow. No dialogue. No motion blur. Shot on 35mm Kodak Vision3 500T. Aspect ratio 3:2.
11. Editorial de moda e fotografia de estilo de vida
A fotografia de moda e estilo de vida é uma das categorias mais valiosas para o GPT Image 2 em produção. O modelo renderiza texturas de tecido — tecido de linho, grão de couro, brilho de cetim — com fidelidade suficiente para comunicar claramente detalhes de estilismo a uma equipe de design.
Capacidade chave: o GPT Image 2 pode renderizar etiquetas de marca em roupas corretamente. Um prompt especificando uma etiqueta que diz 'ÉLISE PARIS' produzirá uma peça de roupa com essa etiqueta legível na imagem.

Prompt
An editorial fashion photograph. Subject: a tall woman in an oversized cream linen suit — wide-leg trousers with sharp creases and a boxy double-breasted blazer. The blazer has a small chest pocket with a folded white pocket square and a brand label visible on the inner lapel reading "ÉTAT LIBRE". She stands on a sun-bleached stone terrace overlooking the Mediterranean Sea, golden hour light behind her creating a natural rim light on her silhouette. Shot on medium format, 80mm equivalent. The linen fabric texture and stitching are clearly visible. Expression: composed, distant, slightly downward gaze.
12. Precisão de cenas do mundo real com ancoragem por pesquisa na web
No modo Thinking, o GPT Image 2 pode pesquisar na web antes de gerar. Isso é importante para prompts que fazem referência a assuntos do mundo real: edifícios específicos, logotipos de marcas, marcos culturais ou designs de produtos atuais.
O limite de conhecimento do GPT Image 2 é dezembro de 2025. Para qualquer assunto que mudou ou surgiu após essa data, a pesquisa na web do modo Thinking mitiga parcialmente a lacuna.
Testamos um marco real renderizado em um estilo artístico específico — um prompt que requer tanto precisão factual sobre a aparência do edifício quanto execução estilística.

Prompt
Search the web for visual references of the Pantheon in Rome, then generate an image of it in loose architectural watercolor style. The painting should accurately reflect the real building's proportions: the massive Corinthian portico with sixteen granite columns in three rows, the triangular pediment, and the cylindrical drum behind it. Medium: loose warm-toned watercolor with deliberate wet-on-wet washes, visible paper texture, and dry brush strokes on the column edges. A small crowd of tourists in simple gestural marks at street level. Overcast soft Roman morning light. No text. Aspect ratio 3:2.
Resultado: A contagem de colunas e as proporções do pórtico na imagem gerada correspondem ao Panteão real — 16 colunas, frontão triangular correto, relação de profundidade correta entre o pórtico e o tambor da rotunda.
Limitações conhecidas
- Limite de conhecimento: dezembro de 2025. Eventos, designs de produtos e figuras públicas surgidas após essa data podem produzir saídas incorretas ou recusadas. A pesquisa na web do modo Thinking atenua isso parcialmente.
- Fundos transparentes não suportados: Para gpt-image-2, o fundo transparente não é atualmente suportado. O parâmetro background: "transparent" não é compatível. Use exportações PNG de outros modelos ou pós-processe.
- Árabe e hebraico com diacríticos completos em tamanhos de ponto pequenos: Aproximadamente um erro de glifo por 20 caracteres em parágrafos densos. Sinalização básica e títulos funcionam de forma confiável.
- Corpo de texto denso em tamanhos de ponto muito pequenos: ~95% de precisão por parágrafo — suficiente para a maioria dos usos, mas requerendo verificação para ativos tipograficamente precisos.
- Edições multi-região complexas: Edições que requerem alterações simultâneas em três ou mais regiões espaciais distintas podem precisar de 2-3 iterações para um resultado limpo.
- Latência do modo Thinking: Gerações multi-imagem complexas podem levar até 2 minutos por lote. Não adequado para requisitos em tempo real ou abaixo de 5 segundos.
- Limites de taxa sob carga de explosão: Cargas de explosão de API pesadas podem acionar limitações de taxa em contas de Nível 1-2. Planeje backoff exponencial em integrações de produção.
Resumo: quando usar o GPT Image 2
| Caso de uso | Padrão de qualidade | Capacidade chave utilizada | Melhor configuração de qualidade |
|---|---|---|---|
| Material criativo com texto na imagem | Pronto para produção | Renderização de texto | Alta |
| Fotografia de produto | Pronto para produção | Fotorrealismo, textura de material | Alta |
| Maquete de embalagem | Pitch/protótipo | Renderização de texto em superfície 3D | Alta |
| Maquete de UI / protótipo de app | Alinhamento com partes interessadas | Raciocínio de layout, precisão de texto | Média |
| Infográfico / diagrama | Pronto para produção | Texto + layout | Média ou Alta |
| Fotografia de retrato | Pronto para produção | Renderização sensível à identidade | Alta |
| Editorial de moda | Protótipo / campanha | Controle de estilo, textura de tecido | Alta |
| Livro infantil / storyboard | Pronto para produção | Consistência multi-imagem (modo Thinking) | Média |
| Cena de marco real | Representação precisa | Ancoragem por pesquisa na web (modo Thinking) | Alta |
| Miniatura para redes sociais | Pronto para produção | Composição + texto na imagem | Baixa ou Média |
| Arte conceitual / fotograma cinematográfico | Exploração criativa | Controle de estilo artístico | Média |
| Iteração rápida / lote de rascunhos | Revisão interna | Velocidade e custo | Baixa |
O GPT Image 2 é a escolha mais forte para qualquer fluxo de trabalho onde a precisão da renderização de texto é um requisito — embalagem, criativo de marketing, infográficos, maquetes de UI, layouts editoriais. É também o único modelo que oferece geração de lotes de múltiplas imagens com continuidade de personagens em uma única chamada de API.
Para fluxos de trabalho que priorizam exploração de estilos artísticos abstratos, velocidade máxima ou o menor custo por imagem em escala, avalie alternativas ao lado do GPT Image 2 em seu conjunto específico de prompts antes de se comprometer com uma pilha.