GPT Image 2 深度评测:12 个真实示例覆盖所有主要使用场景
GPT Image 2——也以 ChatGPT Images 2.0 的名称发布——于 2026 年 4 月 21 日正式上线。这是 OpenAI 首款独立图像生成模型:从 GPT-4o 管线中解耦,以单步推理架构重构,也是 OpenAI 图像模型系列中首款原生集成推理能力的模型。
核心数据:文字渲染准确率 99%+,原生 2K 分辨率(最高支持 4K 横版),宽高比从 3:1 超宽到 1:3 超长竖版,以及——在思考模式下——单个提示词最多可生成 8 张跨批次保持角色一致性的图像。
我们对 12 个生产相关的使用场景进行了测试。以下每个示例均使用 GPT Image 2 并配合所展示的提示词生成。
与 GPT Image 1.5 相比,有哪些变化
| 功能 | GPT Image 1.5 | GPT Image 2 |
|---|---|---|
| 架构 | GPT-4o 图像管线(两阶段) | 独立模型,单步推理 |
| 最大分辨率 | 1536×1024(横版) | 3840×2160(4K 横版) |
| 文字渲染准确率 | ~70%(仅拉丁字母) | 99%+,多语言 |
| 推理集成 | 无 | 原生思考模式,含网络搜索 |
| 多图批量生成 | 不支持 | 单个提示词最多生成 8 张(思考模式) |
| 自然语言编辑 | 不支持 | 描述变更即可,无需蒙版 |
| 宽高比范围 | 1:1 及固定预设 | 3:1 至 1:3,满足约束的任意分辨率 |
| API 模型字符串 | gpt-image-1.5 | gpt-image-2 |
GPT Image 2 并非 GPT-4o 图像更新,而是从头重建:输出 PNG 的元数据不同,推理路径不同,文字渲染管线完全不同。OpenAI 将其定位为为生产工作流设计的「视觉思考伙伴」,而非娱乐性创作工具。
1. 写实人像
人像依然是图像生成最严苛的基准:皮肤纹理、次表面散射、景深和面部比例必须同时准确。GPT Image 2 以模型文档所称的"身份敏感"渲染来处理这些细节——精细的细节贯穿整个画面,而不仅仅是中心裁剪区域。
在我们的测试中,我们使用特定的光照和镜头参数生成了一张特写人像。无后期处理,无放大——直接在高质量设置、1024×1024 下从模型输出。

提示词
A photorealistic close-up portrait of a South Asian woman in her late 20s, soft diffused window light from the upper left, very shallow depth of field with background completely out of focus, warm neutral background, 85mm lens perspective. Ultra-fine skin texture — visible pores, subtle smile lines near the eyes, one small birthmark on the left cheek. Dark brown eyes, natural makeup. Hair loosely pinned, a few strands falling forward. Shot on a medium format digital camera. No filters. No color grading.
结果:皮肤纹理渲染至毛孔级别。光照方向在物理上完全一致——右侧补充阴影、耳廓边缘光——仅凭"来自左上方的窗光"的描述即可实现。胎记和笑纹均清晰可见。这是高质量模式下 1024×1024 的质量下限。
2. 多语言文字渲染
文字渲染是 GPT Image 2 最具定义性的能力,也是它与所有竞争模型之间最大的差距。OpenAI 通过引入排版通道实现了这一突破——该通道在栅格化前先将字形写成矢量形状,而不是在扩散过程中逐像素推断字形形状。
实际效果是:英语、日语、韩语、阿拉伯语、中文、土耳其语和希伯来语文字在绝大多数情况下都能在第一次尝试时正确渲染。密集的多行布局、混合文字海报和含成分列表的包装文案不再需要人工质检才能发货。
我们测试了一张混合日英文字的音乐节海报——这是文字渲染场景中难度较高的测试,因为它要求正确的汉字笔画顺序与干净的拉丁展示字体同时呈现。

提示词
A bold music festival poster. Headline: "音楽の未来" in large brushstroke kanji, centered at the top third. Directly below it in a clean geometric sans-serif: "FUTURE SOUNDS FESTIVAL". Venue and date in smaller white type at the bottom: "Shibuya O-EAST · Tokyo · June 14 2026". Dark background, electric teal and magenta neon glow. All text must be fully legible and correctly formed. No decorative elements that obscure the type.
结果:所有汉字笔画均正确成形。英文标题和场馆行完全清晰可读。一个已知限制:极小字号下含完整变音符的阿拉伯语和希伯来语仍会出现偶发的单字形错误。对于标准尺寸标识和海报文案,准确率已达到生产就绪水平。
3. 产品摄影
电商产品摄影是 GPT Image 2 最具商业价值的使用场景之一。此前每个 SKU 单次拍摄需要花费 500 至 2000 美元的团队,现在可以以极低的成本生成达到摄影棚水准的图像。该模型能够处理反射、表面阴影、材质纹理——玻璃、哑光金属、牛皮纸、陶瓷——以及正确的微距距离景深。
我们测试了高端护肤品平铺拍摄,这是一个基准提示词类别,因为它要求玻璃上的正确镜面高光、可读的标签文字和令人信服的花瓣摆放。

提示词
A high-end skincare flat lay on a smooth white marble surface. Center: a frosted glass serum bottle with a gold dropper cap. The label reads "LUMIÈRE SÉRUM — 30ml" in clean black serif type. Surrounding it: three dried white peonies, scattered rose petals, a small jade facial roller, and a cream-colored linen cloth slightly crumpled in the bottom-left corner. Soft north window light from above-left. Clean drop shadow under each object. No artificial studio look — feels like a magazine editorial. Shot from directly above. 16:9 crop.
结果:标签文字"LUMIÈRE SÉRUM — 30ml"正确渲染,包括带重音的字母 É。磨砂玻璃质感和金色滴管盖高光准确。花瓣摆放呈有机感,而非算法规律感。
4. 带可读标签的产品包装
包装效果图需要最难版本的文字渲染:成分列表、营养成分表、法律文字和品牌排版,全部在具有曲面变形和材质纹理的三维表面上呈现。
在 GPT Image 2 之前,这不借助设计工具合成是不可能实现的。成分面板的单个字符会出现乱码;条形码只是装饰性噪点。GPT Image 2 是第一个能够渲染整个包装效果图并保持文字正确的模型——不仅仅是标题。

提示词
A photorealistic standing coffee bag mockup. The bag is matte black kraft paper with a natural linen texture stripe across the center. Brand name on the front: "ALTIPLANO" in a bold, wide uppercase serif, letterpressed in gold foil. Below it: "Single Origin · Ethiopian Yirgacheffe" in a smaller clean sans-serif. Bottom strip: "Notes: Blueberry · Jasmine · Brown Sugar". The bag has a tin-tie closure at the top and a circular degassing valve on the lower right. Dark studio background with a single dramatic spotlight from above. Realistic paper texture, no plastic sheen.
结果:所有文字元素均正确渲染,包括副标题和风味描述。纸张纹理、锡扣密封和排气阀在物理上合理可信。可直接用于路演 PPT 或电商上架图,无需修图。
5. 含图内文字的营销广告素材
营销团队此前需要在 Figma 或 Photoshop 中将文字叠加到 AI 生成图像上,因为模型文字不可靠。GPT Image 2 消除了这个步骤:标题、CTA 按钮和正文可以在提示词中指定,并将在图像内正确渲染,无需额外的设计流程即可直接部署。
我们测试了社交媒体广告格式——这是此工作流中难度最高的变体,因为它要求在单次生成中同时包含正确的 CTA 文字、产品图像和布局层级。

提示词
A clean social media ad for a premium running shoe brand. Split layout: left half shows a dramatic close-up of a white and electric blue running shoe on a wet asphalt surface reflecting city lights. Right half is a solid dark navy panel. On the navy panel, stacked vertically: bold white headline "RUN FASTER." then a small white separator line, then secondary copy in light grey "Engineered for your fastest 5K." then below that a solid lime green CTA button with the text "SHOP NOW" in black. All text must be perfectly legible. Modern, premium athletic aesthetic.
6. 信息图与步骤图
信息图要求模型同时管理布局、排版层级、图标、方向箭头和信息准确性——这种组合会让大多数图像模型失败。GPT Image 2 在风格化和教学图表方面表现良好。其思考模式还可以在生成过程中搜索网络,将数据驱动的信息图锚定在事实准确信息上,而不是看似合理的近似值。
我们测试了一张带有编号标签和箭头连接器的分步教学图。
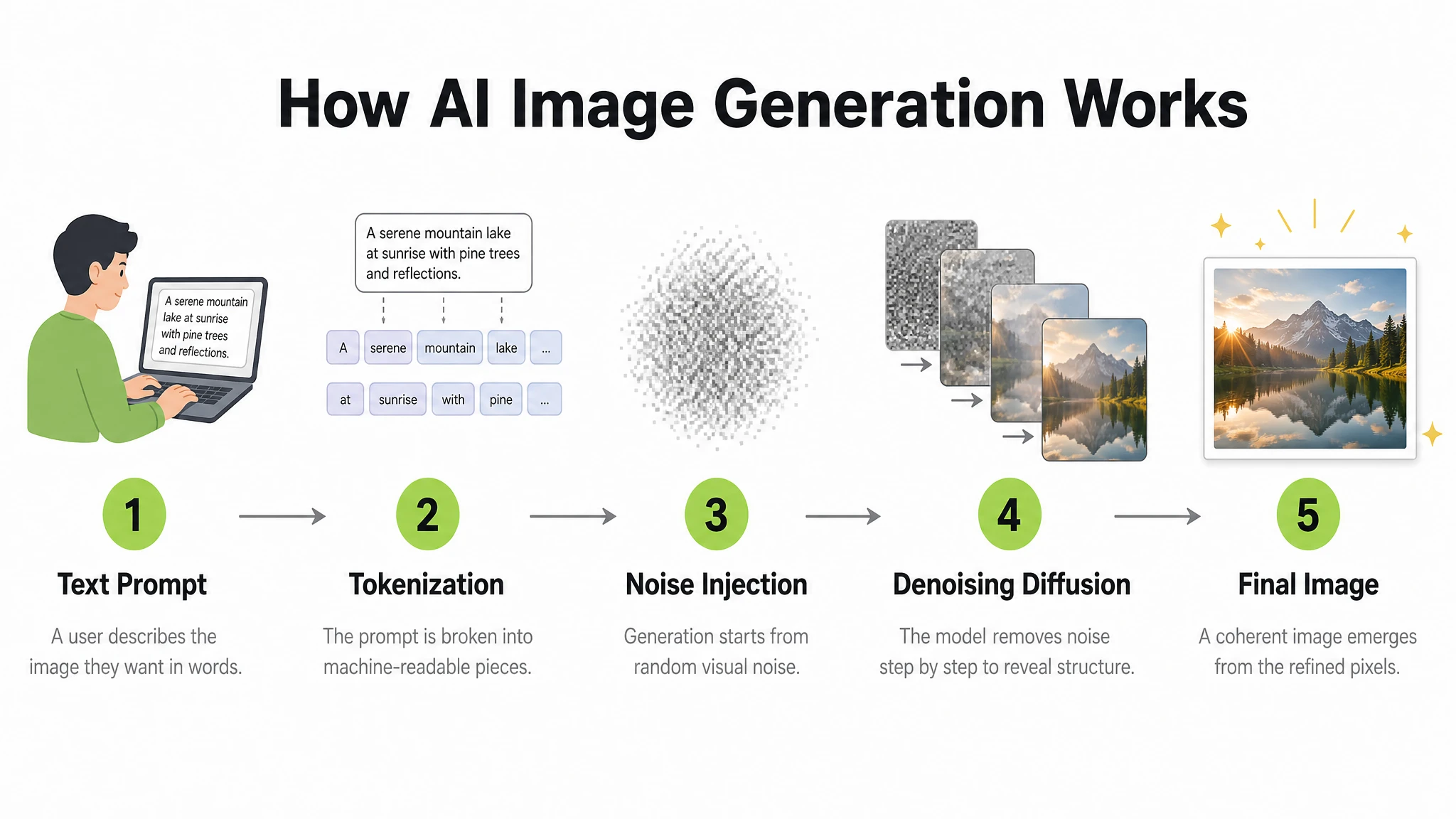
提示词
A clean, modern educational infographic titled "How AI Image Generation Works" showing 5 steps in a left-to-right horizontal flow. Step 1: "Text Prompt" — icon of a person typing. Step 2: "Tokenization" — text being split into tokens. Step 3: "Noise Injection" — abstract Gaussian noise cloud. Step 4: "Denoising Diffusion" — blurry image sharpening. Step 5: "Final Image" — glowing completed photograph. Each step has: a bold number in a lime green circle, a simple flat icon above, the step title in bold dark text, and a one-line description in lighter grey below. Steps connected by clean horizontal arrows. White background. Clear typographic hierarchy. No decorative clutter.
7. UI 原型图与应用界面设计
UI 原型图生成是 GPT Image 2 比任何以往模型都处理得更好的新使用场景。准确的文字渲染、布局推理和图标级细节的结合,使得无需设计工具即可生成可信的应用界面或仪表板——这对于快速原型制作、路演 PPT 和设计团队实际开发前的利益相关者对齐非常有用。
我们测试了移动银行应用仪表板:一个布局复杂的提示词,包含导航标签、账户余额、交易记录行和卡片元素。
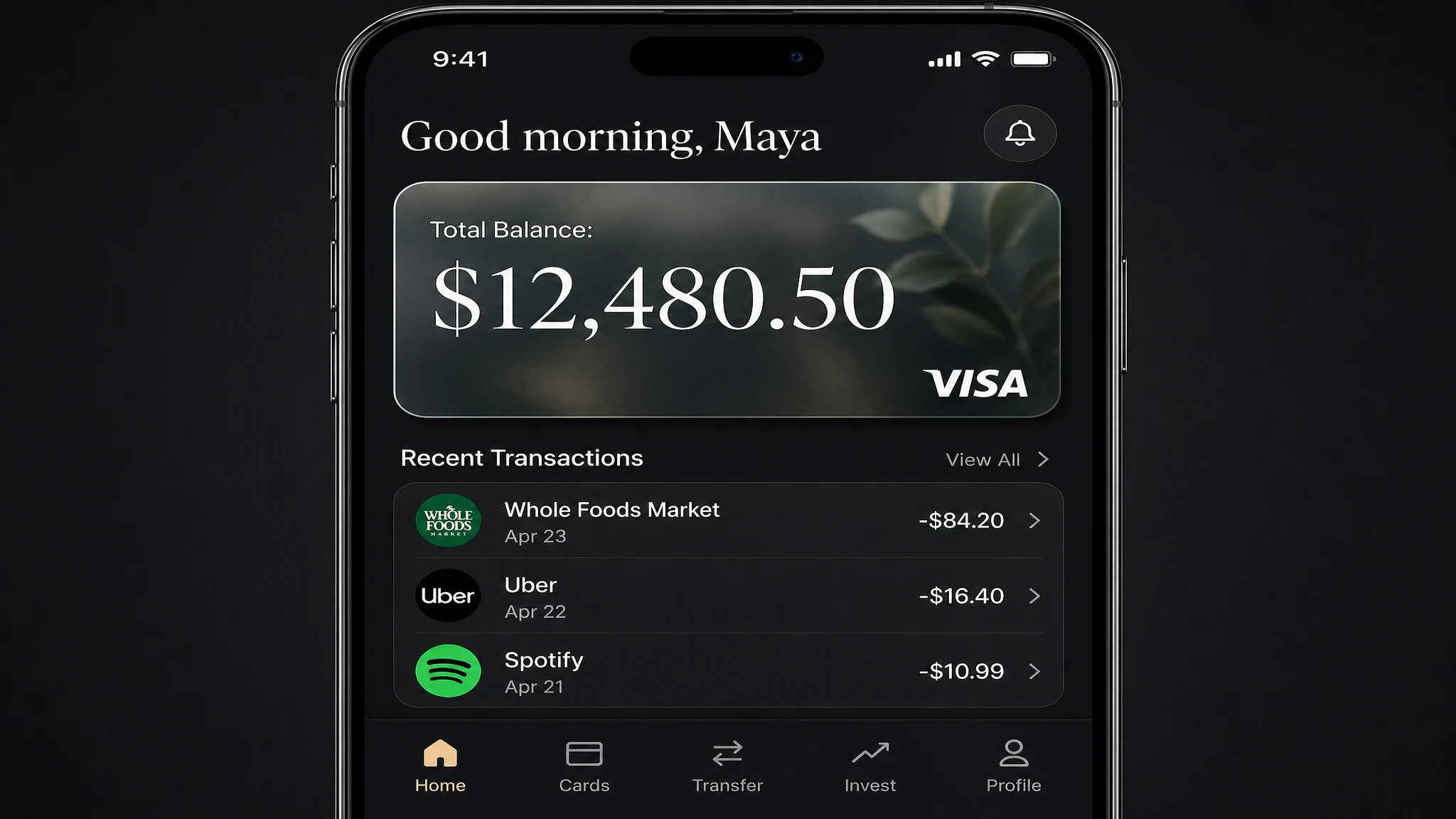
提示词
A photorealistic mobile app UI mockup for a premium digital bank. Dark charcoal background. Top section: user greeting "Good morning, Maya" in white. Below: a frosted glass card element showing "Total Balance: $12,480.50" in a large white serif, with a small visa logo in the bottom right. Below the card: a section titled "Recent Transactions" with three rows — each row has a category icon on the left, merchant name and date in the center, and amount on the right (e.g. "Whole Foods Market · Apr 23 · -$84.20"). Bottom navigation bar with five icons: Home, Cards, Transfer, Invest, Profile. All labels must be legible. Clean, minimal, premium fintech aesthetic.
结果:余额数字、交易记录行和导航标签均正确渲染。磨砂玻璃卡片元素具有准确的半透明效果。适合作为情绪板或利益相关者原型——不是生产就绪的代码,但完全足以在不需要 Figma 文件的情况下传达设计方向。
8. 思考模式:多图一致性
思考模式是 GPT Image 2 最具差异化的能力,也是它与任何其他现有图像生成模型之间最大的差距。启用后,模型在生成前先对提示词进行推理——根据复杂程度花费多或少的计算量——并可以在推理阶段搜索网络。思考模式激活后,可以从单个提示词生成最多 8 张连贯图像,所有输出中的角色、物体和视觉风格保持一致。
这对儿童读物插画、分镜脚本、系列品牌营销活动和游戏概念艺术直接有用。访问思考模式需要 ChatGPT Plus、Pro、商业版或企业版订阅。免费用户只能使用标准生成,没有推理步骤。

提示词
Generate 4 scenes featuring the same character: Chef Milo, a cheerful stocky man in his 40s with a thick red-orange beard, round wire-rimmed glasses, and a white double-breasted chef coat with a small anchovy embroidered on the chest pocket. Scene 1: Milo in a busy open kitchen, plating a dish with tweezers, intense concentration. Scene 2: Milo at a morning market, selecting vegetables, smiling at a vendor. Scene 3: Milo eating a street taco by a food cart, genuine delight on his face. Scene 4: Milo teaching a cooking class, holding a carbon steel wok, students visible in the background. Keep Milo's face, beard, glasses, and coat identical across all four scenes. Cinematic photography style.
这是真正的创新:没有其他图像生成 API 能在单次调用中提供带角色连续性的多图批量输出。对于顺序内容——分镜脚本、插图故事、多场景营销活动——这从根本上改变了生产效率。
9. 自然语言图像编辑
GPT Image 2 通过 /v1/images/edits 接口支持图像编辑。上传一张现有图像并用自然语言描述变更,模型将在不重新生成完整图像的情况下应用针对性编辑,同时保留身份、构图和光照,只修改指定的元素。
背景替换、物体添加、光照变更、服装颜色调整和风格迁移均可通过纯文字描述实现。无需绘制蒙版、无需选择工具、无需图层管理。也可以传入多张参考图像来合成元素——例如将一张图像中的产品放入另一张图像的场景中。

提示词
[Edit instruction applied to an existing studio product shot of a glass perfume bottle on white background] Change the background from the plain white studio background to a warm, rustic wooden table surface with soft dappled sunlight coming from the left. Keep the bottle, its reflections, and its shadow exactly as they are. The new background should feel like a high-end lifestyle photograph taken in a sunlit Parisian apartment.
10. 电影感与艺术风格控制
GPT Image 2 涵盖超过 50 种公认的艺术风格,从写实摄影到油画、水彩、动漫、像素艺术、半调印刷和霓虹赛博朋克。模型严格遵循提示词中的风格描述,不会漂移到通用 AI 美学——这是早期图像生成模型常见的失败模式,无论指定何种具体风格,都会收敛到相似的绘画风格。
我们测试了高对比度电影感静帧:同时指定特定类型、光照设置和色调风格。

提示词
A cinematic still in the style of contemporary neo-noir. A lone figure in a dark trench coat walks down a rain-slicked urban alley at 2am. Reflections of neon signs — one red kanji, one amber "HOTEL" in script — pool on the wet pavement. Shallow depth of field keeps the background signage slightly soft. Color grade: deep teal shadows, warm amber highlights — classic film noir color separation. Low-key side lighting from a practical wall sconce off screen right. The figure's face is partially in shadow. No dialogue. No motion blur. Shot on 35mm Kodak Vision3 500T. Aspect ratio 3:2.
11. 时尚大片与生活方式摄影
时尚和生活方式摄影是 GPT Image 2 在生产中最具价值的类别之一。模型渲染织物纹理——亚麻编织、皮革纹理、缎子光泽——的保真度足以让样式细节清晰传达给设计团队,即使输出尚未达到高端品牌目录的生产就绪水准。
关键能力:GPT Image 2 可以正确渲染服装上的品牌标签。指定标签文字为"ÉLISE PARIS"的提示词,将生成一件图像中该标签清晰可读的服装。这只有 GPT Image 2 才能实现——早期模型会把文字搞乱或者直接省略。

提示词
An editorial fashion photograph. Subject: a tall woman in an oversized cream linen suit — wide-leg trousers with sharp creases and a boxy double-breasted blazer. The blazer has a small chest pocket with a folded white pocket square and a brand label visible on the inner lapel reading "ÉTAT LIBRE". She stands on a sun-bleached stone terrace overlooking the Mediterranean Sea, golden hour light behind her creating a natural rim light on her silhouette. Shot on medium format, 80mm equivalent. The linen fabric texture and stitching are clearly visible. Expression: composed, distant, slightly downward gaze.
12. 借助网络搜索的真实场景准确性
在思考模式下,GPT Image 2 可以在生成前搜索网络。这对于涉及真实世界主题的提示词最为重要:特定建筑、品牌标志、文化地标或当前产品设计。模型不会生成来自训练数据的合理近似,而是查询实时网络图像,并利用所找到的内容来指导生成。
GPT Image 2 的知识截止日期为 2025 年 12 月。对于该日期后发生变化或出现的任何主题——新产品设计、2026 年事件、近期更新的品牌形象——思考模式的网络搜索可以部分弥补这一差距。对于训练窗口内的主题,视觉准确性的提升是显著的。
我们测试了以特定艺术风格渲染的真实地标——这个提示词既要求建筑外观的事实准确性,又要求风格执行。

提示词
Search the web for visual references of the Pantheon in Rome, then generate an image of it in loose architectural watercolor style. The painting should accurately reflect the real building's proportions: the massive Corinthian portico with sixteen granite columns in three rows, the triangular pediment, and the cylindrical drum behind it. Medium: loose warm-toned watercolor with deliberate wet-on-wet washes, visible paper texture, and dry brush strokes on the column edges. A small crowd of tourists in simple gestural marks at street level. Overcast soft Roman morning light. No text. Aspect ratio 3:2.
结果:生成图像中的立柱数量和门廊比例与实际万神殿相符——16 根立柱、正确的三角形山花、门廊与鼓形圆筒之间正确的深度关系。没有网络基础,早期模型会生成一个看似合理的"通用罗马神庙",与真实建筑存在显著偏差。
已知局限性
- 知识截止日期:2025 年 12 月。该日期之后出现的事件、产品设计和公众人物可能产生不正确或被拒绝的输出。思考模式的网络搜索可在一定程度上弥补这一限制。
- 不支持透明背景:gpt-image-2 目前不支持透明背景。将 background 参数设置为"transparent"不受支持。如需透明背景,请使用其他模型导出 PNG 或进行后期处理。
- 含完整变音符的阿拉伯语和希伯来语小字号:在密集段落中大约每 20 个字符会出现一个错误。基本标识和标题可靠支持。
- 极小字号的密集正文(如报纸 5pt 正文):每段约 95% 的准确率——大多数场景已足够,但在对排版精度要求极高的资产中需进行验证。
- 复杂多区域编辑:涉及三个或更多不同空间区域同时修改的编辑操作,可能需要 2–3 次迭代才能得到清晰的结果。
- 思考模式延迟:复杂多图生成每批可能需要长达 2 分钟。不适合实时或 5 秒内的响应需求。
- 爆发负载下的速率限制:高频率的 API 爆发请求可能触发 Tier 1–2 账户的速率限制。在生产集成中请规划指数退避策略。
总结:何时选用 GPT Image 2
| 使用场景 | 质量标准 | 核心能力 | 最佳画质设置 |
|---|---|---|---|
| 含图内文字的营销广告 | 生产就绪 | 文字渲染 | 高 |
| 产品摄影 | 生产就绪 | 写实感、材质纹理 | 高 |
| 包装效果图 | 路演/原型 | 3D 表面文字渲染 | 高 |
| UI 原型图/应用原型 | 利益相关者对齐 | 布局推理、文字准确性 | 中 |
| 信息图/图表 | 生产就绪 | 文字 + 布局 | 中或高 |
| 人像摄影 | 生产就绪 | 身份敏感渲染 | 高 |
| 时尚大片 | 原型/营销活动 | 风格控制、织物纹理 | 高 |
| 儿童读物/分镜脚本 | 生产就绪 | 多图一致性(思考模式) | 中 |
| 真实地标场景 | 准确呈现 | 网络搜索基础(思考模式) | 高 |
| 社交媒体缩略图 | 生产就绪 | 构图 + 图内文字 | 低或中 |
| 概念艺术/电影感静帧 | 创意探索 | 艺术风格控制 | 中 |
| 快速迭代/草稿批量 | 内部审查 | 速度和成本 | 低 |
GPT Image 2 是任何对文字渲染准确性有要求的工作流的最优选择——包装、营销素材、信息图、UI 原型图、编辑排版。它也是唯一能在单次 API 调用中提供带角色连续性的多图批量生成的模型。
对于优先考虑抽象艺术风格探索、最高速度或最低单图成本的工作流,在确定技术栈之前,请先对您的实际提示词集测试替代方案与 GPT Image 2 的效果。